This is an overview of probabilities and statistics topics.
Random variables are numerical outcomes of random phenomena, with the range of possible values represented by that variable.
For example, in the coin toss experiment, the possible outcomes of tails and heads get mapped to 0 and 1 respectively, then the random variable X will have possible values of 0 or 1.
On the other hand, when rolling a fair die, the possible values for the random variable are 1, 2, 3, 4, 5, and 6, because the die has 6 sides so those are the possible outcomes.
There are two types of random variables: discrete and continuous.
If a random variable can take only a finite number of values, then it must be discrete. The variables described in the previous examples are all discrete.
"A continuous random variable is one that takes an infinite number of possible values. Continuous random variables are usually measurements-" -- (Yale University, n.d.)
A continuous random variable is a random variable with a set of possible values (known as the range) that is infinite and uncountable. Continuous random variables are usually measurements, such as height and weight, because they can assume any value within a specified range.
As covered in the section about random variables, they are numerical outcomes of random phenomena. Probability density functions (PDFs) are then the functions that describe the probability of a random variable.
The probability distribution function for
a random variable
For example,
consider again the experiment of rolling a fair die.
As described above,
the random variable
Therefore, the probability distribution for this experiment can be summarized as follows:
| Outcome | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Probability | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 |
As you'll see next, probability density functions can be discrete or continuous.
One common discrete probability distribution function is the binomial distribution.
"A binomial distribution describes the probability of success or failure of an experiment that is repeated multiple times." (Glenn, 2021).
Therefore, the binomial is a type of distribution that only displays two possible outcomes.
A coin toss has only two possible outcomes: heads or tails. Therefore, a coin toss experiment can be described by the binomial distribution.
A uniform distribution, also called a rectangular distribution, is a probability distribution that has constant probability.
Rolling a single die is one example of a discrete uniform distribution.
A die roll has six possible outcomes: 1, 2, 3, 4, 5, or 6.
There is a
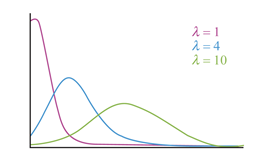
Another type of discrete probability distribution is the Poisson distribution. The Poisson distribution can be used to predict the probability of events occurring within a fixed interval based on how often they have occurred in the past.
The Poisson distribution is given by:
where
This parameter also dictates the shape of the Poisson distribution.
Here is an example of how to use the Poisson distribution.
"A textbook store rents an average of 200 books every Saturday night. Using this data, it is possible to predict the probability that more books will sell (perhaps 220 or 240) on the following Saturday nights" (Glenn, 2013).
The normal probability distribution,
a widely used continuous probability distribution,
is actually a family of distributions with differing means (indicated by
So widely known it has its own note document. Read there for more information.
The normal distribution is given by:
The normal distribution is symmetric about the mean, which is the same as the median and the mode.
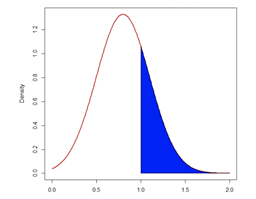
"Because there are infinite values that the random variable
could assume, the probability of taking any particular value is zero. (Nicholas School of the Environment, 2021)."
Therefore, values are often expressed in ranges.
For example,
the probability that a random variable
A closely related distribution is the t-distribution, which is also symmetrical and bell-shaped but it has heavier “tails” than the normal distribution.
It is highly similar to the normal distribution, in fact it's a special case of the normal distribution. For more information, see the Normal Distribution: T-Distrbution note.
The logistic distribution is used for various growth models and a type of regression known, appropriately enough, as logistic regression (Wikipedia 2021).
The standard logistic distribution is a continuous distribution on the set of real numbers with distribution function F given by:
The exponential distribution is a widely used continuous distribution. It is often used to model the time elapsed between events.
A continuous random variable
where
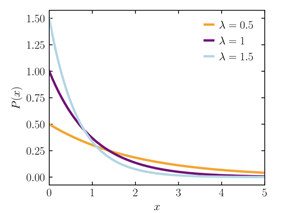
To get an intuitive feel for this interpretation of the exponential distribution, suppose you are waiting for an event to happen. For example, you are at a store and are waiting for the next customer. In each millisecond, the probability that a new customer will enter the store is very small. Imagine that a coin is tossed each millisecond. If it lands on heads, a new customer enters. The time until a new customer arrives will approximately follow an exponential distribution.
One of the most important characteristics to
a lot of probability distributions is the mean and variance.
A mean is the average, or expected value, of a distribution.
The variance is a measure of how spread out the distribution is,
or how much the values vary from the mean.
The mean is denoted by the Greek letter
Their relationship is given by:
Where the